Frequency distribution
In statistics, the frequency or absolute frequency of an event is the number of times the observation has occurred/recorded in an experiment or study.[1]: 12–19 These frequencies are often depicted graphically or in tabular form.


Types
The cumulative frequency is the total of the absolute frequencies of all events at or below a certain point in an ordered list of events.[1]: 17–19
The relative frequency (or empirical probability) of an event is the absolute frequency normalized by the total number of events:

The values of for all events can be plotted to produce a frequency distribution.

In the case when for certain , pseudocounts can be added.

Depicting frequency distributions
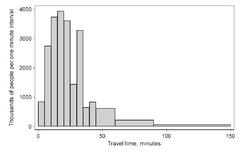


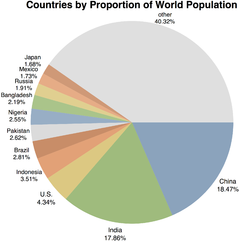
A frequency distribution shows a summarized grouping of data divided into mutually exclusive classes and the number of occurrences in a class. It is a way of showing unorganized data notably to show results of an election, income of people for a certain region, sales of a product within a certain period, student loan amounts of graduates, etc. Some of the graphs that can be used with frequency distributions are histograms, line charts, bar charts and pie charts. Frequency distributions are used for both qualitative and quantitative data.
Construction
- Decide the number of classes. Too many classes or too few classes might not reveal the basic shape of the data set, also it will be difficult to interpret such frequency distribution. The ideal number of classes may be determined or estimated by formula: (log base 10), or by the square-root choice formula where n is the total number of observations in the data. (The latter will be much too large for large data sets such as population statistics.) However, these formulas are not a hard rule and the resulting number of classes determined by formula may not always be exactly suitable with the data being dealt with.
- Calculate the range of the data (Range = Max – Min) by finding the minimum and maximum data values. Range will be used to determine the class interval or class width.
- Decide the width of the classes, denoted by h and obtained by (assuming the class intervals are the same for all classes).



Generally the class interval or class width is the same for all classes. The classes all taken together must cover at least the distance from the lowest value (minimum) in the data to the highest (maximum) value. Equal class intervals are preferred in frequency distribution, while unequal class intervals (for example logarithmic intervals) may be necessary in certain situations to produce a good spread of observations between the classes and avoid a large number of empty, or almost empty classes.[2]
- Decide the individual class limits and select a suitable starting point of the first class which is arbitrary; it may be less than or equal to the minimum value. Usually it is started before the minimum value in such a way that the midpoint (the average of lower and upper class limits of the first class) is properly[clarification needed] placed.
- Take an observation and mark a vertical bar (|) for a class it belongs. A running tally is kept till the last observation.
- Find the frequencies, relative frequency, cumulative frequency etc. as required.
The following are some commonly used methods of depicting frequency:[3]
Histograms
A histogram is a representation of tabulated frequencies, shown as adjacent rectangles or squares (in some of situations), erected over discrete intervals (bins), with an area proportional to the frequency of the observations in the interval. The height of a rectangle is also equal to the frequency density of the interval, i.e., the frequency divided by the width of the interval. The total area of the histogram is equal to the number of data. A histogram may also be normalized displaying relative frequencies. It then shows the proportion of cases that fall into each of several categories, with the total area equaling 1. The categories are usually specified as consecutive, non-overlapping intervals of a variable. The categories (intervals) must be adjacent, and often are chosen to be of the same size.[4] The rectangles of a histogram are drawn so that they touch each other to indicate that the original variable is continuous.[5]
Bar graphs
A bar chart or bar graph is a chart with rectangular bars with lengths proportional to the values that they represent. The bars can be plotted vertically or horizontally. A vertical bar chart is sometimes called a column bar chart.
Frequency distribution table
A frequency distribution table is an arrangement of the values that one or more variables take in a sample. Each entry in the table contains the frequency or count of the occurrences of values within a particular group or interval, and in this way, the table summarizes the distribution of values in the sample.
This is an example of a univariate (=single variable) frequency table. The frequency of each response to a survey question is depicted.
| Rank | Degree of agreement | Number |
|---|---|---|
| 1 | Strongly agree | 22 |
| 2 | Agree somewhat | 30 |
| 3 | Not sure | 20 |
| 4 | Disagree somewhat | 15 |
| 5 | Strongly disagree | 15 |
A different tabulation scheme aggregates values into bins such that each bin encompasses a range of values. For example, the heights of the students in a class could be organized into the following frequency table.
| Height range | Number of students | Cumulative number |
|---|---|---|
| less than 5.0 feet | 25 | 25 |
| 5.0–5.5 feet | 35 | 60 |
| 5.5–6.0 feet | 20 | 80 |
| 6.0–6.5 feet | 20 | 100 |
Joint frequency distributions
Bivariate joint frequency distributions are often presented as (two-way) contingency tables:
| Dance | Sports | TV | Total | |
|---|---|---|---|---|
| Men | 2 | 10 | 8 | 20 |
| Women | 16 | 6 | 8 | 30 |
| Total | 18 | 16 | 16 | 50 |
The total row and total column report the marginal frequencies or marginal distribution, while the body of the table reports the joint frequencies.[6]
Interpretation
Under the frequency interpretation of probability, it is assumed that as the length of a series of trials increases without bound, the fraction of experiments in which a given event occurs will approach a fixed value, known as the limiting relative frequency.[7][8]
This interpretation is often contrasted with Bayesian probability. In fact, the term 'frequentist' was first used by M. G. Kendall in 1949, to contrast with Bayesians, whom he called "non-frequentists".[9][10] He observed
- 3....we may broadly distinguish two main attitudes. One takes probability as 'a degree of rational belief', or some similar idea...the second defines probability in terms of frequencies of occurrence of events, or by relative proportions in 'populations' or 'collectives'; (p. 101)
- ...
- 12. It might be thought that the differences between the frequentists and the non-frequentists (if I may call them such) are largely due to the differences of the domains which they purport to cover. (p. 104)
- ...
- I assert that this is not so ... The essential distinction between the frequentists and the non-frequentists is, I think, that the former, in an effort to avoid anything savouring of matters of opinion, seek to define probability in terms of the objective properties of a population, real or hypothetical, whereas the latter do not. [emphasis in original]
Applications
Managing and operating on frequency tabulated data is much simpler than operation on raw data. There are simple algorithms to calculate median, mean, standard deviation etc. from these tables.
Statistical hypothesis testing is founded on the assessment of differences and similarities between frequency distributions. This assessment involves measures of central tendency or averages, such as the mean and median, and measures of variability or statistical dispersion, such as the standard deviation or variance.
A frequency distribution is said to be skewed when its mean and median are significantly different, or more generally when it is asymmetric. The kurtosis of a frequency distribution is a measure of the proportion of extreme values (outliers), which appear at either end of the histogram. If the distribution is more outlier-prone than the normal distribution it is said to be leptokurtic; if less outlier-prone it is said to be platykurtic.
Letter frequency distributions are also used in frequency analysis to crack ciphers, and are used to compare the relative frequencies of letters in different languages and other languages are often used like Greek, Latin, etc.
See also
- Count data
- Cross tabulation
- Cumulative distribution function
- Cumulative frequency analysis
- Empirical distribution function
- Law of large numbers
- Multiset multiplicity as frequency analog
- Probability density function
- Probability interpretations
- Statistical regularity
- Word frequency
References
- ^ a b Kenney, J. F.; Keeping, E. S. (1962). Mathematics of Statistics, Part 1 (3rd ed.). Princeton, NJ: Van Nostrand Reinhold.
- ^ Manikandan, S (1 January 2011). "Frequency distribution". Journal of Pharmacology & Pharmacotherapeutics. 2 (1): 54–55. doi:10.4103/0976-500X.77120. ISSN 0976-500X. PMC 3117575. PMID 21701652.
- ^ Carlson, K. and Winquist, J. (2014) An Introduction to Statistics. SAGE Publications, Inc. Chapter 1: Introduction to Statistics and Frequency Distributions
- ^ Howitt, D. and Cramer, D. (2008) Statistics in Psychology. Prentice Hall
- ^ Charles Stangor (2011) "Research Methods For The Behavioral Sciences". Wadsworth, Cengage Learning. ISBN 9780840031976.
- ^ Stat Trek, Statistics and Probability Glossary, s.v. Joint frequency
- ^ von Mises, Richard (1939) Probability, Statistics, and Truth (in German) (English translation, 1981: Dover Publications; 2 Revised edition. ISBN 0486242145) (p.14)
- ^ The Frequency theory Chapter 5; discussed in Donald Gilles, Philosophical theories of probability (2000), Psychology Press. ISBN 9780415182751 , p. 88.
- ^ Earliest Known Uses of Some of the Words of Probability & Statistics
- ^ Kendall, Maurice George (1949). "On the Reconciliation of Theories of Probability". Biometrika. 36 (1/2). Biometrika Trust: 101–116. doi:10.1093/biomet/36.1-2.101. JSTOR 2332534.